
최근 자율주행 및 로봇 산업에서 가장 주목받는 AI 기술 중 하나가 바로 VLA 모델입니다. VLA는 Vision-Language-Action의 약자로, 시각 정보와 언어 정보를 결합해 행동까지 연결하는 차세대 자율주행 AI 알고리즘입니다. 이 모델은 인간처럼 주변을 ‘보고’, ‘이해하고’, ‘행동하는’ 방식으로 물리적 환경과 상호작용합니다. 2025년을 기점으로 VLA는 자율주행 대형 모델 2.0 시대를 여는 핵심 기술로 자리 잡고 있습니다.

VLA 모델이란 무엇인가?
VLA 모델은 Vision(시각), Language(언어), Action(행동)을 하나의 통합된 시스템으로 묶는 엔드투엔드 AI 프레임워크입니다. 전통적인 자율주행 시스템은 시각 인식, 경로 계획, 제어 등을 각각 다른 모듈에서 처리했지만, VLA는 이를 하나의 대형 AI 모델로 통합합니다. 이를 통해 시스템이 더욱 유연해지고, 다양한 환경에서도 강인한 성능을 발휘할 수 있습니다.
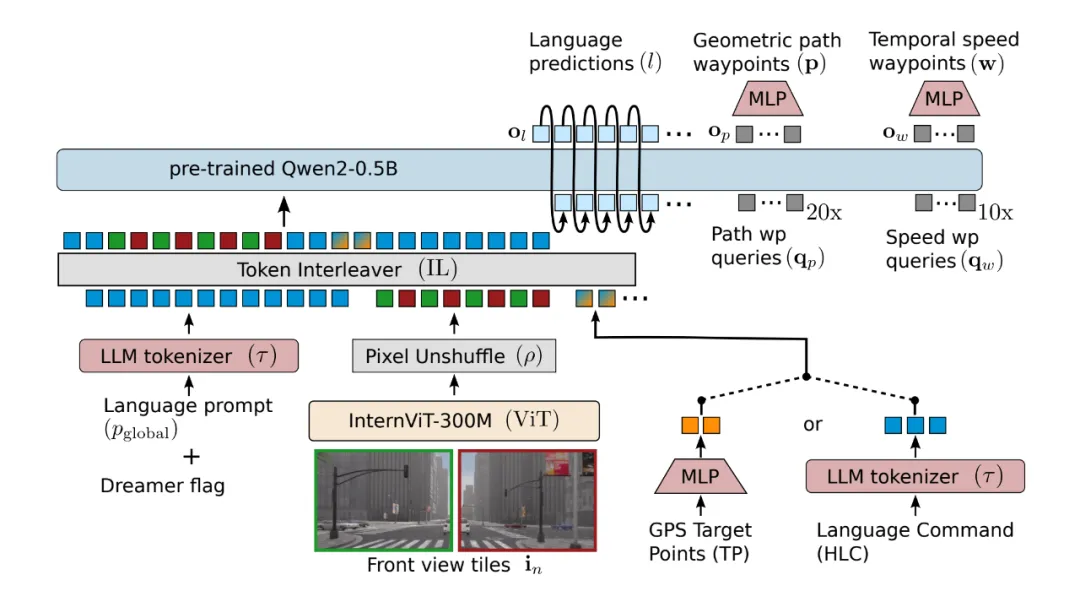
왜 지금 VLA 모델이 주목받는가?
1. 대규모 사전 학습으로 데이터 효율 극대화
VLA는 이미지와 자막, 영상 설명 같은 시각-언어 데이터셋을 활용해 사전 학습(pretraining) 됩니다. 이렇게 학습된 모델은 적은 양의 실차 데이터만으로도 뛰어난 성능을 보입니다. 기존 자율주행 시스템처럼 수천만 개의 반복적인 주행 데이터를 수집하지 않아도 되며, 데이터 효율성 면에서 매우 뛰어납니다.
2. 인간 수준의 자연어 이해
"앞 신호등에서 좌회전", "앞의 주차장에 진입해"와 같은 자연어 명령을 해석하고 행동으로 전환할 수 있는 능력은 VLA 모델의 큰 강점입니다. 이는 단순한 기호 기반 제어 시스템에서 벗어나, 인간과 자연스럽게 소통할 수 있는 자율주행 시스템으로의 진화입니다.
3. 시각+언어+행동 통합으로 시스템 간소화
기존 시스템은 인식, 해석, 판단, 제어 등 여러 단계로 나뉘어 있었지만, VLA 모델은 이를 하나의 신경망 모델에서 통합 처리합니다. 이를 통해 개발 복잡성을 줄이고, 실시간 반응 속도도 향상됩니다.
4. 로봇 기술과의 통합 가능성
VLA 모델은 자율주행차 뿐 아니라 휴머노이드 로봇, 산업용 로봇 등 다양한 로봇 인공지능 분야에도 응용될 수 있습니다. 하나의 알고리즘으로 다양한 물리적 플랫폼에서 행동을 생성하는 것이 가능해지기 때문입니다.

VLA 모델의 구조와 구성 요소
VLA 모델은 크게 세 가지 모듈로 구성됩니다.
- 시각 인코더 (예: ViT, CLIP, DINOv2)
카메라나 LiDAR를 통해 주변 환경을 인식하고, 시각 정보를 개념적 토큰(token) 으로 전환합니다. - 언어 모델 (LLM) (예: LLaMA-2, Qwen, Deepseek)
인간의 언어를 고차원 임베딩으로 변환하고, 이를 시각 정보와 함께 해석해 행동의 목적을 추론합니다. - 정책 모듈 또는 플래너
최종적으로 차량 또는 로봇이 어떤 동작을 취할지 결정하는 모듈입니다. 이 모듈은 고차원의 명령을 저차원의 실제 동작으로 변환합니다.
이 세 가지가 통합되어 작동하면서, VLA 모델은 "앞에서 우회전해"와 같은 언어 지시를 듣고, 실제 차량을 조작하거나 로봇이 물체를 옮기도록 만드는 것입니다.

실제 산업에서의 VLA 적용 사례
Wayve (영국)
자율주행 스타트업 Wayve는 2023년 LINGO-1을 시작으로 VLA 기반 자율주행 모델을 상용화 단계에 도입했습니다. 이 모델은 운전자의 질문에 대해 주행 이유를 자연어로 설명하며, Uber 및 Nissan과 협력해 L4 로보택시 상용화를 진행 중입니다.
Li Auto(理想汽车) – 중국
리샹은 2024년부터 VLM(Vision-Language Model) 논문을 공개하며 VLA 모델을 적극 도입하고 있으며, 2025년에는 NVIDIA Thor 칩 기반으로 VLA 모델 탑재 차량을 출시할 예정입니다. VLM은 클라우드에서 운영되며 차량 단말기와 통신해 행동을 결정합니다.
Xpeng(小鹏)
샤오펑은 최근 G7 모델 발표에서 720억 파라미터 규모의 클라우드-기반 VLA 구조를 소개했습니다. 총 3개의 Turing 칩으로 2200TOPS의 연산 능력을 확보해, 차량 내 실시간 VLA 연산이 가능하도록 구성하고 있습니다.
Figure AI, NVIDIA Groot
로봇 기술 기업들도 VLA를 적극 채택하고 있습니다. Figure AI의 Helix와 NVIDIA의 GR00T N1은 각각 고속 제어기(S1)와 고차원 계획자(S2)를 결합한 구조로, 실제 환경에서 휴머노이드 로봇의 동작을 실시간으로 제어하는 데 성공했습니다.
VLA 모델, 자체 개발이 필요한가?
결론부터 말하자면, 필수는 아닙니다. 특히 핵심인 LLM(대형 언어 모델)은 오픈소스 또는 상용 API를 활용할 수 있습니다. 현재 대부분의 기업들은 아래와 같이 외부 LLM을 조합해 VLA를 구성합니다.
- 해외: OpenAI, Meta, Google의 PaLM-E 등 사용
- 중국: Deepseek, 알리바바 Qwen 등을 주로 사용
각 기업은 이러한 공개 모델을 조합하고, 자사 차량 혹은 로봇에 맞는 정책 모듈만 최적화하여 실제 제품에 적용하고 있습니다.
마무리: VLA는 Physical AI의 핵심
VLA 모델은 단순한 알고리즘의 발전을 넘어, 인간처럼 세상을 인식하고 반응하는 체현형 인공지능(Physical AI) 의 구현입니다. 이는 자율주행 기술뿐 아니라, 향후 로봇 산업, 스마트 홈, 헬스케어, 산업 자동화 등에서도 폭넓게 활용될 수 있습니다.
기술이 아무리 앞서더라도, 실제 사용자 경험과 서비스 완성도가 따라줘야 진정한 가치를 발휘할 수 있습니다.
앞으로 VLA 기반의 자율주행 AI와 로봇 인공지능 기술이 얼마나 빠르게 현실 속으로 들어올지 주목해 볼 때입니다.
자율주행자동차, 어디까지 왔나?
자동차가 스스로 길을 찾고, 스스로 속도를 조절하는 시대. 자율주행자동차는 단순한 기술 트렌드를 넘어 미래 모빌리티의 핵심으로 떠오르고 있습니다. 그런데 ‘자율주행’에도 레벨이 있다
rainbowsemicon.com
폭스바겐 중국전략 – 전기화·지능화에 대응하는 자세
“전기차와 스마트카가 지배하는 중국 시장에서 폭스바겐이 다시 우뚝 설 수 있을까?”자동차 업계, 투자자, 소비자 모두가 궁금해하는 이 질문에 대한 해답을 찾기 위해 폭스바겐 중국전략을
rainbowsemicon.com
중국 전기차의 진화 !!🔧 상하이 모터쇼의 ‘十字路口’에서 방향을 제시한 텐즈 Z 콘셉트카
“기술로 럭셔리를 정의하다. 중국 전기차, 그다음 챕터로”2025년 상하이 모터쇼는 단순한 신차 발표의 무대를 넘어, 세계 자동차 산업의 흐름과 철학이 충돌하는 무대였다. 특히 5.1H관에서 마
rainbowsemicon.com
'반도체 이야기와 산업트랜드' 카테고리의 다른 글
| AR글래스 화면이 보이는 원리, 한 번에 이해하기! (3) | 2025.06.13 |
|---|---|
| 애플의 반격, 비전 프로 2세대가 될까? (5) | 2025.06.13 |
| 전기차 필수 DC-DC 컨버터, 왜 필요한가? (4) | 2025.06.09 |
| 드론용 이미지센서 완벽 이해! (3) | 2025.06.09 |
| 중국 전기차 신차 출시! 샤오펑G7 공개 – 전기 SUV 시장에 새로운 바람 (6) | 2025.06.08 |



